这是Whirl开的新坑之一,目的一是督促自己每天都来读文献,二是为了能够更好的记录下来所读文献的内容,三是为了给网站填一些东西哈哈哈。
至于这个坑的名字,Whirl目前还没有想好,先叫做Paper Flash,意思是这些文章在我读的时候不会特别细致去钻研,而是我写的时候也要概括文章的大意,希望读到此文的你也能够在一首歌的时间内读完所有内容。每天的文章最少为2篇,最多不限。如果你在阅读的时候有什么建议,欢迎随时评论,评论是不需要登录的哦。
另外,考虑到可能会有某些竞争的关系,文章的发布时间通常会晚一个月,但由于第一篇属于试水,所以会晚一周。也就是当你看到这篇文章时,应该正好是十一长假后,所以不要以为是我时间写错了。
废话不多说,我们开始吧
[title]2021.09.26[/title]
Evaluating Progress on Machine Learning for Longitudinal Electronic Healthcare Data
Arxiv 文章主要讲述了19种ML方法在MIMIC-III的一个Benchmark数据集上的表现。基本结论是利用深度学习得到的结果与直接利用logistics regression相比没有好太多。主要比较了四个任务,死亡率预测、ICU住院时间、病症和 Patient decompensation (这个我感觉是代谢失常,应该是死亡后24小时内一些指标的变化,是二分类问题)。在这四个任务中,随着时间的增加,不同方法的指标并没有什么显著的增长。
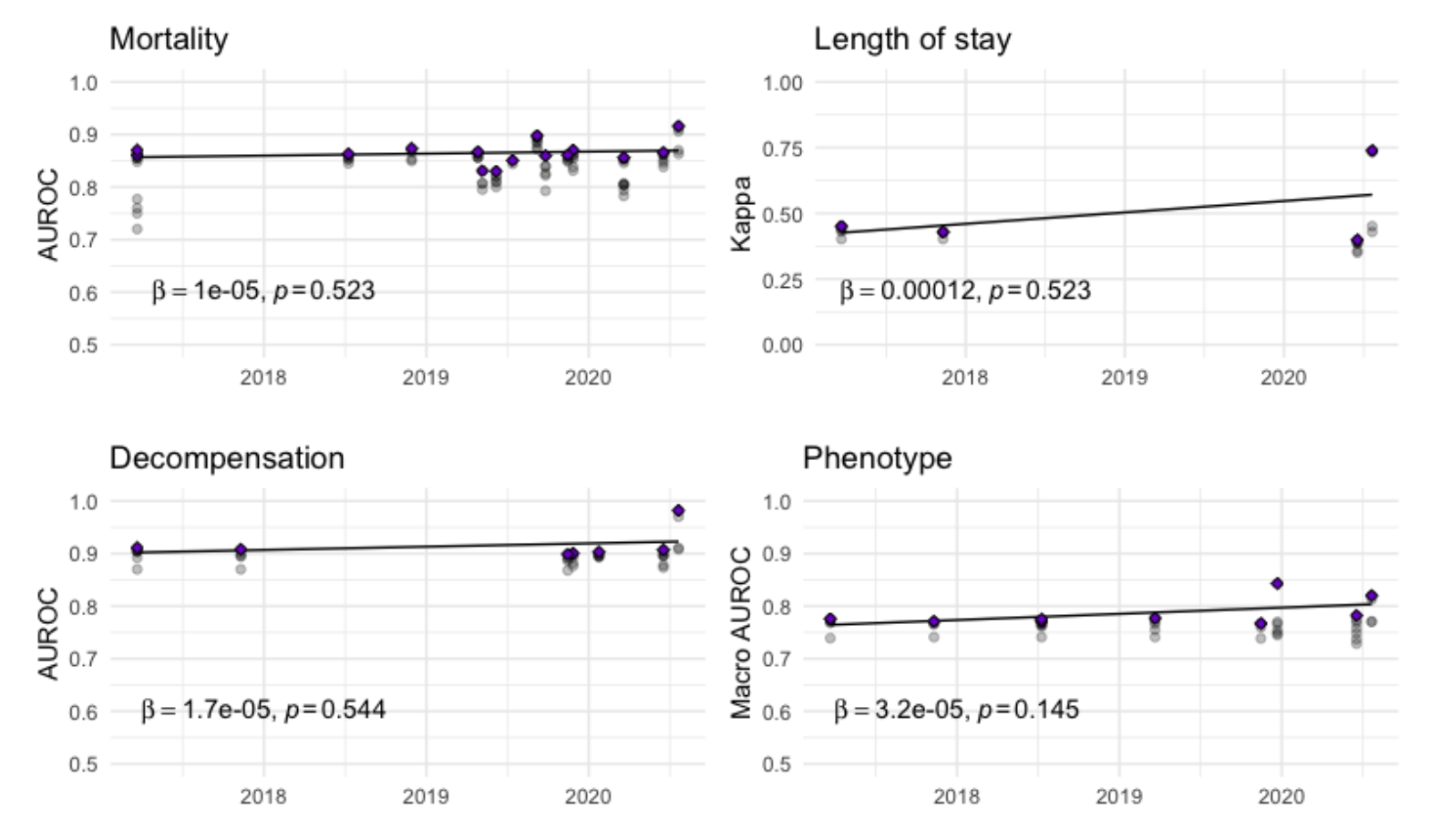
文章中提到了很多很有意思的benchmark,比如有ECG的PTB-XL, a large publicly available electrocardiography dataset,MIMIC-III的 Multitask learning and benchmarking with clinical time series data。我觉得nature scientific data期刊是很好的数据来源地。
The myth of generalisability in clinical research and machine learning in health care
The Lancet Digital Health viewpoint 文章提到了机器学习普适性的问题,有个例子:在医院A训好的模型在医院B失败了,原因是两家医院对于抗生素的政策不同,从而模型是在有抗生素偏倚背景下训练得到的。所以有时候模型的generalisation 可能并不是一个很好解决的问题。以及对一个模型来说,我们要考虑的背景因素其实有很多,想model所有的事情是不现实的,但如果能够从机器学习模型里发现一些规律(其实就是人能够解释的东西),那也很有意义。有点像知识发现,但感觉比较困难,我觉得还是训一个模型来讲故事比较靠谱。
Patient Trajectory Modelling in Longitudinal Data: A Review on Existing Solutions
CBMS2021 方法类综述文章,主要说明了当前方法如何建模病人的轨迹推断问题:我有一个0-t时刻都有数据的样本,我需要推测样本在t+1时刻的状态。这个文章关心三个问题:1)什么样的方法在使用?2)什么类型的数据要被使用?3)现有方法如何考虑数据时间成分。对现有方法的总结如下:
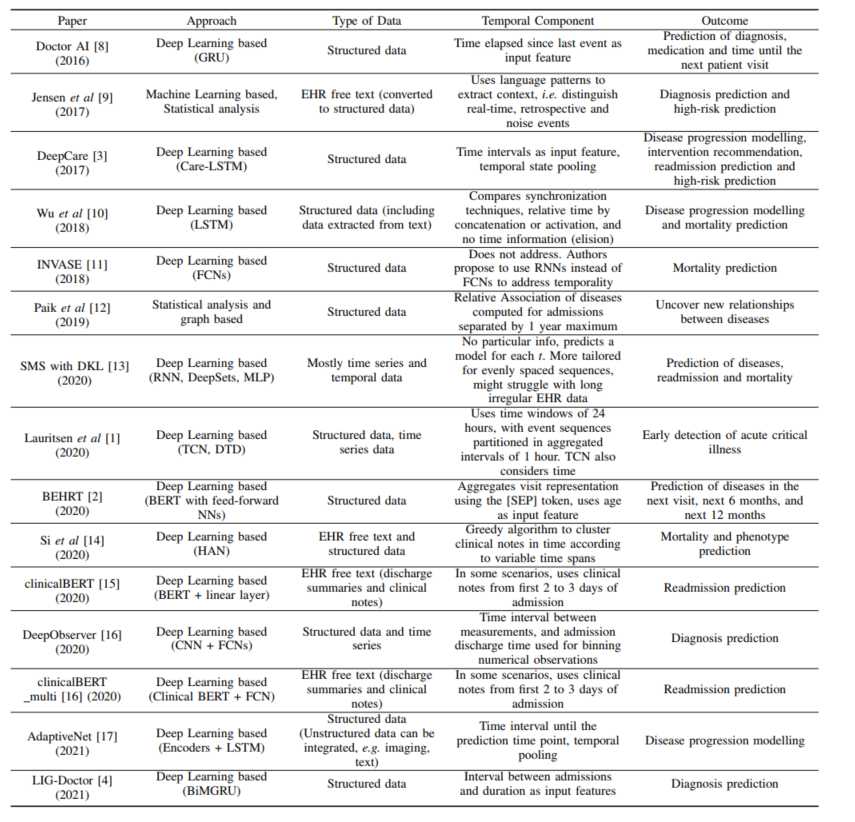
从目的来看,很多方法都是对病人接下来的疾病情况,再入院几率,死亡率进行了预测,其实和大部分工作的结果是一致的。而对时间的数据处理上看,无非是这么几类:
- Time related features as input:这个实际上就是没有时间信息,而只是提取的特征认为是和时间相关的
- Temporal state pooling:在模型中间对时间状态做了pooling,听起来就是深度学习会用的办法
- Synchronization techniques and binning strategies:在输入的过程做时间序列的分割,然后对于事件记录在这个时间段上是否发生
- Fixed time window:只选取固定时间内发生的事情
总的来说,这篇文章是从方法学上对时序数据的处理进行了归纳,感觉写的不是特别好,太关注于模型上的细节而缺失了对整体任务的定义。
[title]2021.09.27[/title]
Network-based machine learning in colorectal and bladder organoid models predicts anti-cancer drug efficacy in patients
NC 2020 一篇关注癌症药物效果biomarker发现的文章,作者所有的数据都是从网上下载的,作为一个纯分析的文章发在NC上还是很厉害的,Pipeline如下:
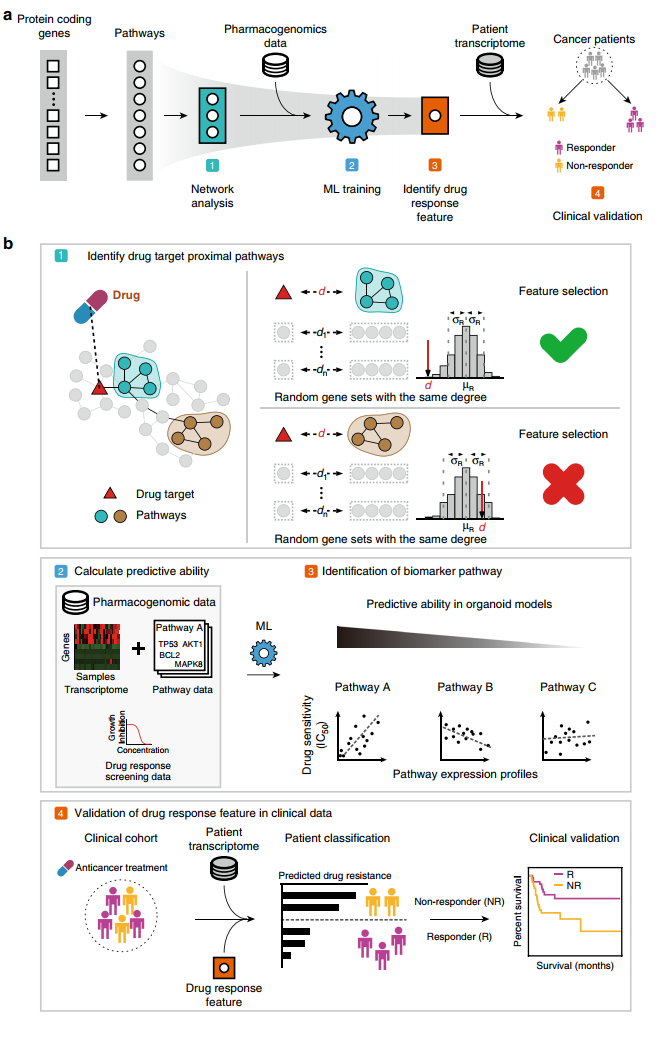
先在网络上找到了与药物相关的基因,然后再找基因所在的pathway,通过permutation的方法找到一些pathway。然后我们去看不同病人在这些pathway上的表达,利用ML方法用pathway数据去预测药物的IC50。这些都是在类器官数据上做的。然后根据找到的biomarker,我们把吃药的病人分为两组,去看不同病人生存期的变化。文章主要是从找到的biomarker来解释药物效果的,对ML的预测结果没有着重关注,文章也提到,多种ML方法找到的biomarker是一致的。
与这个工作类似的工作还有:2014年在GB上的Clinical drug response can be predicted using baseline gene expression levels and in vitro drug sensitivity in cell lines
研究癌症的好处是有基因表达数据,在临床上数据的获取比较方便,所以我们可以把基因表达和药物的互作考虑进来。对于心脏病,可能心电图是突破口,但这样本身生物信息的成分会比较少。
Development and Validation of a Machine Learning Individualized Treatment Rule in First-Episode Schizophrenia
JAMA Network Open 2019 一个proof of concept的工作,比较偏统计。就是为每个病人生成所谓的individualized treatment rule (ITR),也就是治疗方案,然后根据后12个月的死亡情况或者是否换药来确定某一种药物的成功率。当然文中也提到了这种思路的limitation就是不是随机对照实验,会存在很多协变量。模型首先在训练集上利用患者的人口统计学和临床特征,包括医学和精神病学的共病情况作为输入,预测每个药物的成功率,然后在测试集上给每个病人选分数最高的药,一个人只吃一种药的情况去估计ITR的有效性。
总的来说有点像药物推荐,但没有考虑药物之间的关系,对药物处理后病人体征的变化没有过多的设计。
[title]2021.09.28[/title]
Use of Machine Learning for Predicting Escitalopram Treatment Outcome From Electroencephalography Recordings in Adult Patients With Depression
JAMA Network Open 2020 回答的问题是:通过分析患者静息状态的脑电信号,是否可以预测抑郁症患者经过依他普仑治疗后病情是否会有所改善? 机器学习模型用了SVM,样本有122个,输入数据就是脑电图,标签是通过某个表查到的病人疾病情况变化。所有病人用了同样的药物剂量。也就说,这是一个无药物改变影响的实验。中间又有一些统计分析,感觉JAMA Network 这个期刊的套路都差不多。
From Real-World Patient Data to Individualized Treatment Effects Using Machine Learning: Current and Future Methods to Address Underlying Challenges
Clinical Pharmacology & Therapeutics 2021 一篇从因果推断+机器学习角度对现有个性化诊疗工作做总结的文章。总的来说,我能考虑到的它都考虑到了,主要提出了一套理论把药物试验的结果装了进去:不吃药是一种反事实 counterfactuals ,我们要预测的其实是事实与反事实之间的差别。差别越大,就证明我们的药物越有效,思路的优势是考虑的是差异变化,回避了绝对值难以估计的问题。文章还提到了个性化的药物实验与传统RCT实验的区别:我们可以准确的考虑到不同人特征下药物实验的区别。
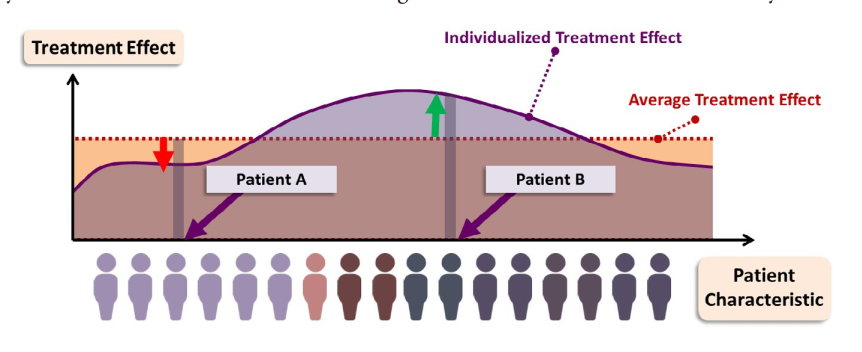
对于因果推断模型,输入一般都是二值向量,表示吃没吃药,输出也往往是一些二值的效果,或者评判指标。另外输入的药物变量也比较少,往往是看几种特定的treatment对某一个或者多个指标的影响。模型的验证往往是在仿真数据上做的。不过有个疑问,如果病人的状态都可以通过仿真得到了,那为什么还要model effects?
因果推断的工作也分为单一时间点推测和序列推测,每种模型也有相应的深度学习模型,都需要去细细的看每一个细节。同时文章通篇提到了很多有关协变量,方差变化的术语,非常在意数据是否干净,这也是和传统机器学习不一样的。单一时间点模型有:
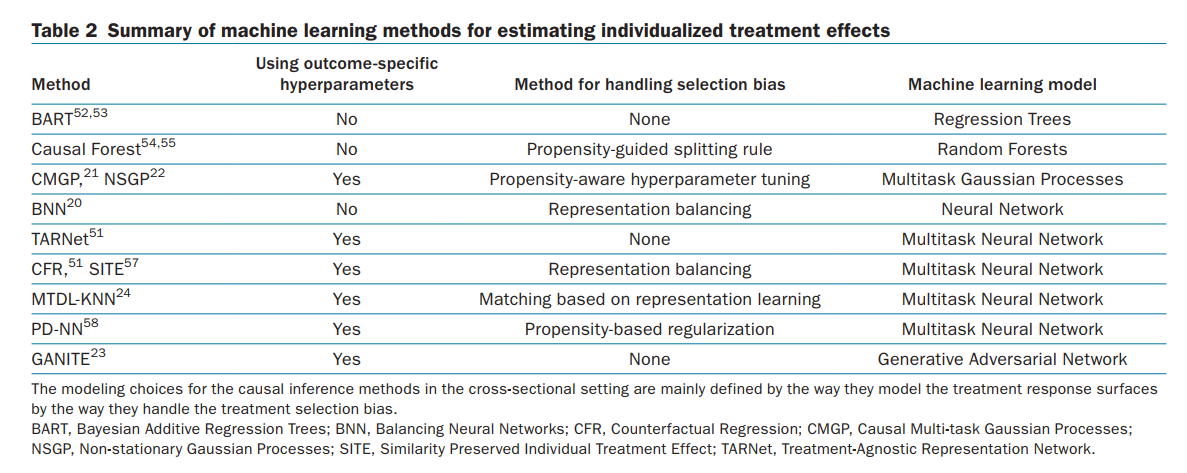
多时间点模型有:
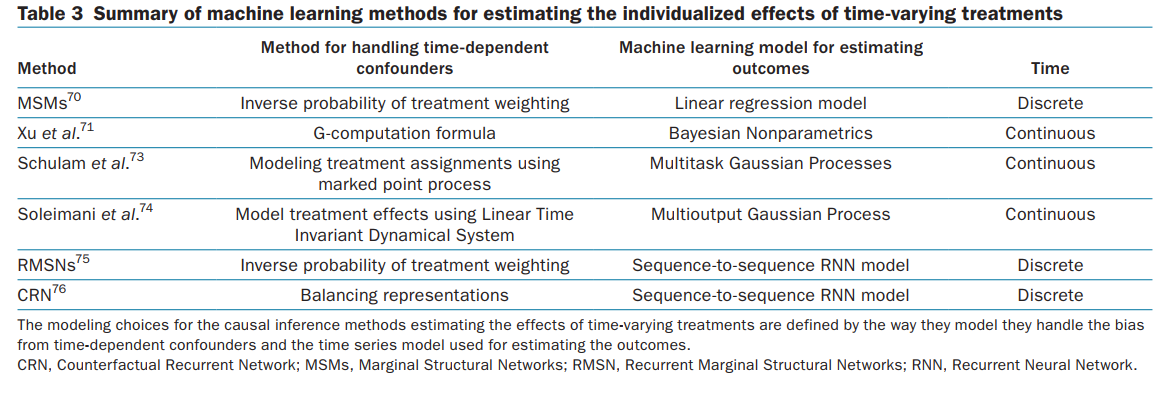
总的来说这个方向的工作有60多篇,还是挺多的。接下来一段时间应该要看看。
[title]2021.09.29[/title]
Clinical intelligence: New machine learning techniques for predicting clinical drug response
Computers in Biology and Medicine 2018 还是传统利用基因表达数据估计药物效果的,原来这样的工作还是有挺多的,并且好像都是在癌症样本上。这篇的特点主要是利用了Transfer Learning,作者说当前训练集可能存在正负样本不均衡等问题,而通过迁移学习可以构建正负样本均衡的数据集。但作者并没有考虑预测药物之间的相似性,直接从数据本身做迁移学习不知道核心原理是什么。不过2018年好像正是迁移学习比较热的一年,也可以理解。
Eight ways machine learning is assisting medicine
nature medicine 2021 一篇来着与美国医生的临床短文,8个方向感觉并不是分的很开,具体有
- 重建疾病的发生发展过程,但也没具体说怎么做;
- 提供假设检验,这个指的是用基因表达数据预测患者用药后的死亡率;
- 寻找受试病人。利用算法找到某些人可以参加药物实验
- 聚合大数据,呃实在是不知道这个和机器学习的关系,可能他们认为信息处理都是机器学习?还可以在临床诊所提供诊疗,但这部分有比较大的现实与文章的鸿沟。
- 提供诊断,这种又是对图像,心电做感知。总的来说,我越来越感觉机器学习这一波热潮解决的是对人类结构化数据的解读,但是真正的人工智能应该是有推理成分的
- 提升预后,一大堆预测模型
- 病人状态监控,利用手表等信息监控病人状态
- 多个领域科学家的协同,TUM的生物信息学家研究发现很多文章都是不同领域合作的
文章比较短,说的几个点子和自身的研究方向还是有些区别,当做底蕴积累吧。
[title]2021.09.30[/title]
Using a Human Patient Simulation Mannequin to Teach Interdisciplinary Team Skills to Pharmacy Students
American Journal of Pharmaceutical Education 2007 一篇和教育有关的文章,主要是研究Human Patient Simulation(HPS)在教育中的影响,HPS像是一个有记录了很多种规则的专家系统,可以模拟病人的情况。文中提到了训练医生开药的场景:病人具有高血压和头疼,有一个护士会报告病人的情况,医生根据当前情况和一些实验室的指标,来确定病人要吃什么药。有意思的是护士会在旁边协助他们,而病人则会每几分钟就问大家他要吃什么药。所以从这个角度看,虚拟药物实验也许在教学上会有比较大的用处。而这个HPS系统更像是一个有实体的数基生命,文章结论是与教育学相关的,不是重点。
* Human Patient Simulat ion
About SimMan & SimMan 3G | Healthcare Simulation | HealthySimulation.com
Human Patient Simulator | Healthcare Simulation | HealthySimulation.com
今日的第二篇文献总结变成了是对HPS的深入了解。这两个网站上是对HPS产品的介绍,这些人体模型可以模拟心电图、心音、呼吸音、肠音,血压和脉搏。“迈阿密大学医学教育研究中心为学习者提供更深入的实践,设计了真人大小的哈维心肺模拟器,它将展示心脏病的所有生理症状。这个人体模型还有30种心脏状况和200多种不同的床边检查结果。”
Harvey Manikin Cardiopulmonary Simulator | Healthcare Simulation | HealthySimulation.com
一个专门用于心脏病的模型,基本来说是用物理模型模拟了不同疾病情况下,病人身体上的变化,确实不是数学上机理的建模,但是能把这些临床的体征描述的这么逼真,还是很厉害的。视频连接在

文章评论