2021年11月16日
An Empirical Framework for Domain Generalization in Clinical Settings
CHIL 2021 迁移学习方面的文章,文章提出在医学场景中,经常会遇到模型泛化能力较差的情况,而作者在读之前的文章中,发现经验风险最小( empirical risk minimization,ERM)模型的泛化能力在一些数据集上比现在的已知模型效果都要好,于是作者就在医疗文本和医学图像上测试了8种迁移学习的模型,最终得到了类似的结论,ERM模型的效果并不比新提出的模型差。
所谓的ERM的模型,就是直接将多个环境中的训练数据集成起来训练一个模型,属于最简单的baseline模型。文章回顾了域泛化模型的发展历程,一种思路叫鲁棒估计,做法是最小化最大风险,这和统计学习的思路比较像;还有一种思路是减少样本中的环境因素,将样本分成领域特定部分和通用部分。然后拿通用部分去做OOD的泛化;作者还认为图像中的augmentation也是一种泛化方式,另外还有一种叫IRM的算法将问题求解变为梯度下降,从而可以在大数据上进行训练。
作者还提到了一个叫做Fairness的词,不是很清楚这个词的含义。
在2.4节,作者提出几个验证迁移学习的Benchmark:DomainBed,WILDS。前人在这几个数据集上的验证都这证明了一些方法效果都不如最传统的ERM好。
2021年11月17日
Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning
Nature Biomedical Engineering 2018 利用深度学习在眼底照相图片上识别心血管风险。高血压导致了血管发生了一些变化,会在眼底照相上体现出动脉,静脉上的变化,从而我们可以从眼底照相估计心血管风险。作者用到了UKbioBank的数据,做法就是用图片去预测风险因素:年龄,低压和高压等。
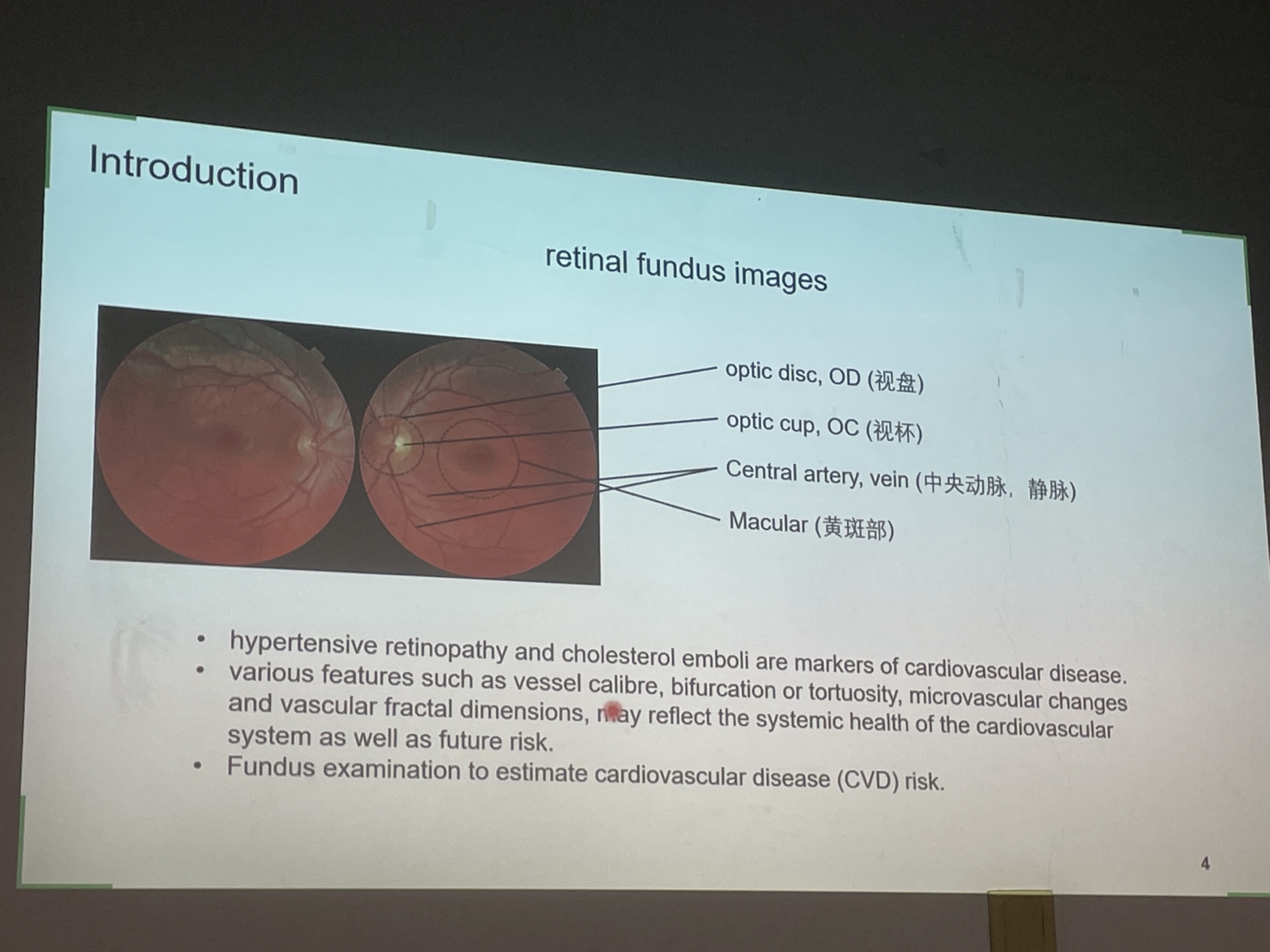
A deep-learning system for the assessment of cardiovascular disease risk via the measurement of retinal-vessel calibre
先从眼底照相中找到了血管的直径,然后根据直径再进一步寻找和新血管的风险。作者先用一个软件手工标出了眼底照相的4项血管指标,然后再训练了一个CNN去拟合这4种指标。之后,作者又进一步用这四种指标和心血管事件进行了相关性分析,发现这四种指标和心血管事件存在不同的正负相关性。但是相关系数都不是很高。
2021年11月18日
Development of a risk score for QTc-prolongation: the RISQ-PATH study
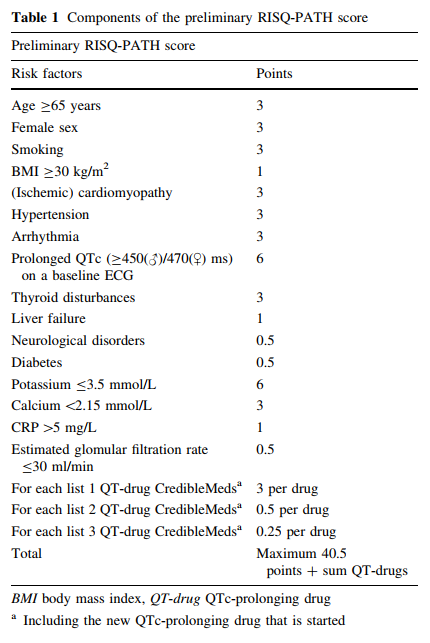
Int J Clin Pharm 2017 这篇文章是11月6日读的文章的1.0版本,也是最初的RISQ-PATH模型,主要是对危险因素进行评分累加,然后决定患者是否为高风险患者,评分表如下所示,相比之前的pro-QTc评分,作者对不同用药习惯进行了权重设定:
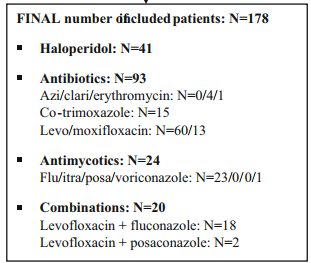
作者收集到鲁汶大学医院一共564个病人的数据,经过筛选后,还有178个病人,作者按照不同的吃药方法将这些人分为了4组:
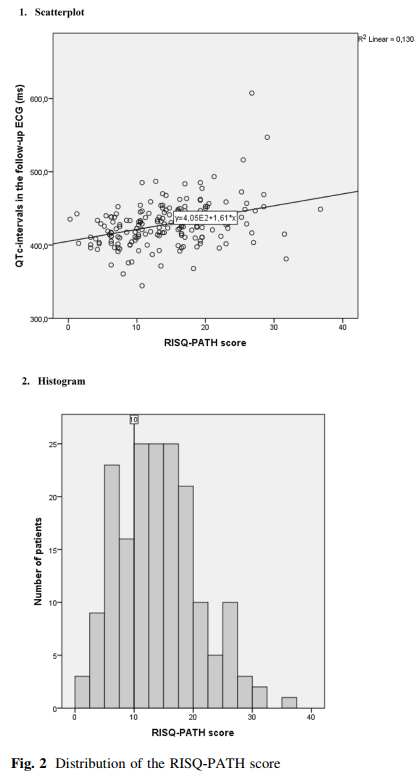
评分超过10分的被作者认为是高风险人群,这样一个简单的评分达到了96.2%的灵敏度和98%负样本检测率(negative predictive value)。作者宣称这项研究是智能信号和决策支持系统的第一步,该系统可以帮助医疗专业人员以负责任的方式处理qtc延长的风险。下面是一些简单的实验结果:
2021年11月19日
Development of a risk model for predicting QTc interval prolongation in patients using QTc‑prolonging drugs
International Journal of Clinical Pharmacy 2018
背景:许多药物都存在延长ECG中的QT间期并增加心律失常的风险,而这种风险和患者额外的风险因子有关。
目标:开发并验证一个能够预测在合格ECG上QT间期的模型
研究场地:荷兰
方法:收集了从2013年到2016年的所有的用至少一种与QT延长相关药物的心电图。在训练集,与QT延长相关的风险因素利用多元逻辑斯特回归模型来确定,回归系数Beta值代表风险分数。在验证集计算了灵敏度和特异度。
主要度量方法:QT>500被记录QT延长
结果:12,949个训练集和6391个验证集。QT发生延长但是没有风险因素的病例占验证集的2.7%,而有高风险的病例占26.1%。AUROC为0.71,灵敏度和特异度分别为0.81和0.48。
结论:建立了一个风险模型,有助于进行医疗辅助决策。
2021年11月20日
Uncertainty-Aware Deep Learning-Based Cardiac Arrhythmias Classification Model of Electrocardiogram Signals
computers 2021 利用深度学习识别ECG有助于减轻医生的负担,但是在实际应用中,医疗决策的场景中需要对决定由不确定度的分析。在聚类或分类任务中,常用fuzzy方法进行分析;而在神经网络中,常利用贝叶斯方法对输出的不确定度进行估计,作者就是想在对心电图进行识别时,引入对不确定度的估计。对于给定数据集D,在参数w下预测值的概率分布为:
$p\left(y^{*} \mid x^{*}, \mathbf{D}\right)=\int p\left(y^{*} \mid x^{*}, \mathbf{w}\right) p(\mathbf{w} \mid \mathbf{D}) d \mathbf{w}$
公式的第二项刚好可以被Dropout描绘,而第一层就是多做几遍。。。
故事讲完了,作者具体的做法试试用到了称为"MC dropout"的一层,一般我们在做inference时会去掉dropout层,但作者保留了这层并做了N次inference,那么这样一个样本就会有100种结果,取其中的均值最为最终预测,而取100次输出的和熵为不确定度的衡量:记每次估计为$p(y_i|x,\mathbf{D}$,那么熵为:
$\mathcal{H}(y \mid x, \mathbf{D})=-\sum_{i=1}^{K} p\left(y_{i} \mid x, \mathbf{D}\right) \log p\left(y_{i} \mid x, \mathbf{D}\right)$
最后作者说自己的模型AUROC能到0.99,然后模型的不确定度由于没有现成的统计指标,作者说主要考虑正确但不确定(CU),错误但确定(IC)这两种情况的表现就好了。具体来说需要设定一个阈值来划分确定和不确定,然后再统计上述事件在测试集的概率。
作者用的是GRU模型,文中也提到了GRU和LSTM的区别。
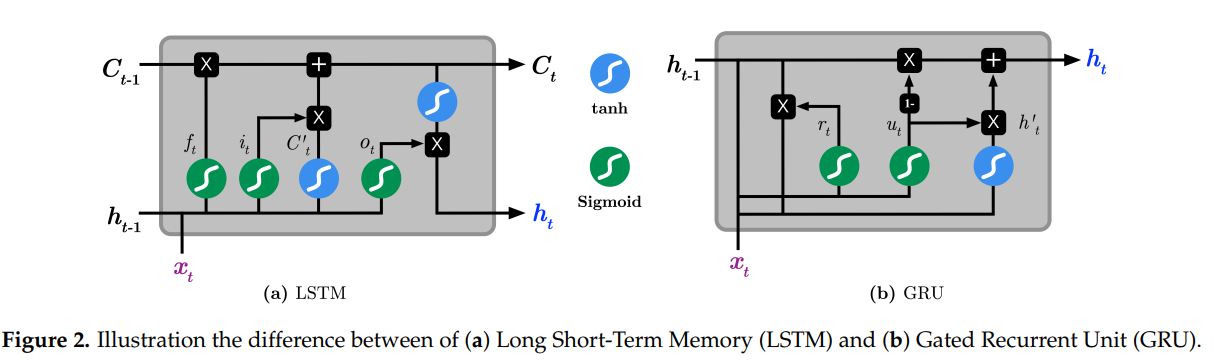
2021年11月21日
Artificial intelligence capable of detecting left ventricular hypertrophy: pushing the limits of the electrocardiogram?
ESC 2020 这篇文章是对“Comparing the performance of artificial intelligence and conventional diagnosis criteria for detecting left ventricular hypertrophy using electrocardiography”文章的评论。原文章主要通过CNN和DNN模型结合起来处理心电图数据以及病人的特征数据,在分类左心室肥大任务上达到了0.88的AUROC,远远高于之前提到的人工衡量标准。而在原文章中,作者还利用sailency 方法对模型的结果进行了可视化,找到了心电图中关键信号的位置。
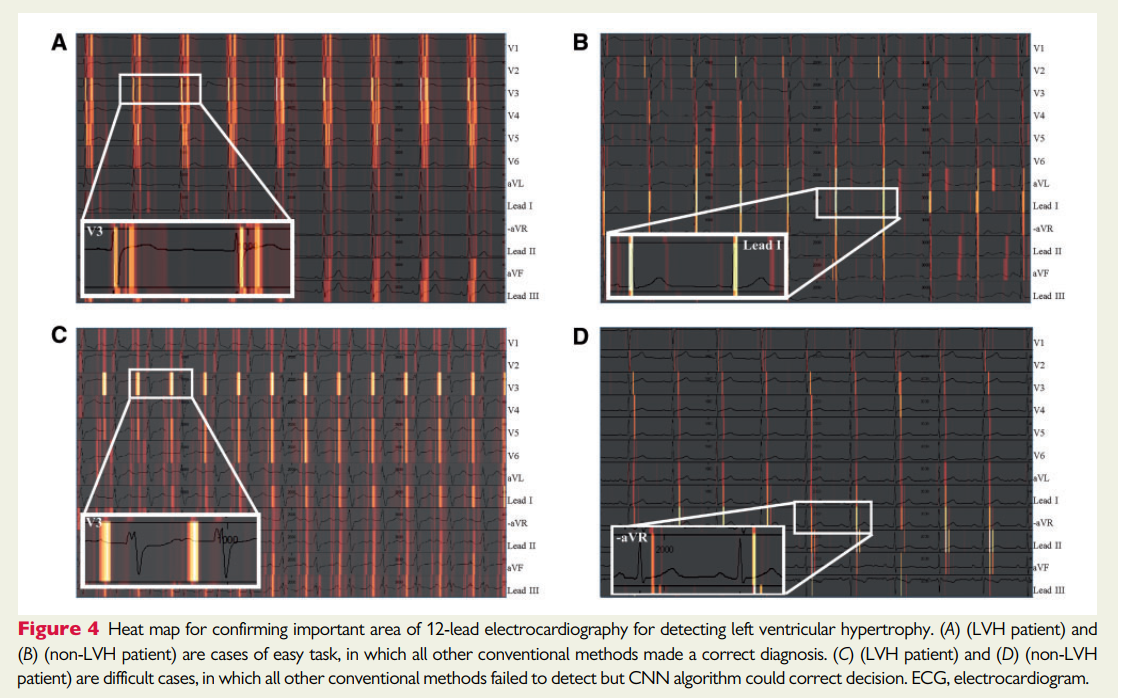
总的来说利用ECG检测是否发生左心室肥大(需要心脏超声),是一个比较有实用价值的方向,而作者又有2个医院一共2万个病人的配套数据,数据规模也非常大,从而可以发在一个比较好的期刊上。
2021年11月22日
Cancer Metastasis Detection With Neural Conditional Random Field
MIDL 2018 乳腺癌的诊断往往需要通过全片图像准确地发现淋巴结的转移,深度卷积神经网络(CNNs)的最新进展在医学图像分析,特别是在计算组织病理学方面取得了显著的成功。由于WSIs的尺寸大得离谱(outrageous),大多数的方法都是将一张幻灯片分割成许多小图像patch,并对每个patch独立进行分类。但是这些方法没有考虑不同图像patch之间的空间关系,在这篇文章中,作者提出了一种端到端的深度卷积CRF网络,NCRF通过直接整合在CNN特征提取器上的全连接CRF来考虑相邻斑块之间的空间相关性。与不考虑空间相关性的基线方法相比,本文提出的NCRF框架获得的斑块预测概率图具有更好的视觉质量。在Camelyon16数据集上,我们还证明了我们的方法在癌症转移检测方面优于基线,在测试集上实现了平均FROC评分0.8096。整个网络的Pipeline比较简单,如下图所示:
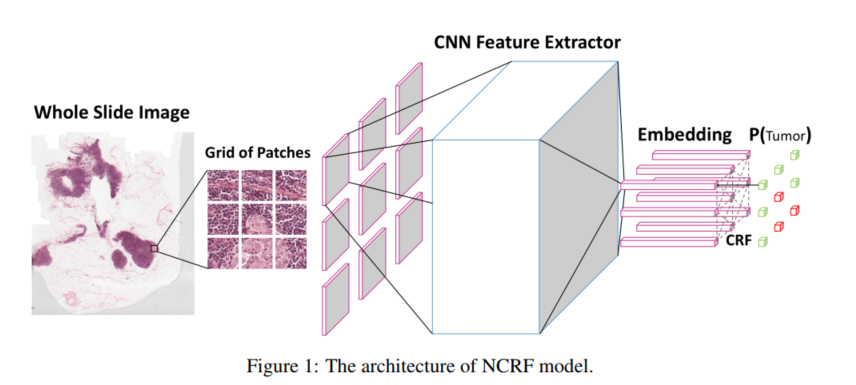
在这里对条件随机场(CRF)模型进行一些简单的介绍,本质上我们需要明确一点,CRF归根结底是想解决$P(\mathbf{Y}|\mathbf{X})$整个概率的计算,这里的$\mathbf{Y}=(Y_1,Y_2,...,Y_n)$,而$\mathbf{X}$是和这些$Y$是一一对应的向量,也就是说,我们在给定隐状态X时,Y的条件分布是怎么样的,而这其中概率最大的Y就是我们要求的。那我们该怎么定义这样的概率呢?一般来说,我们借鉴了物理能量场的概念,对于每一种$\mathbf{Y_i}|\mathbf{X_i}$,我们定义能量为$E_i$,那么有
$P(\mathbf{Y}|\mathbf{X})=\frac{E_i}{E_1+E_2+...+E_n}$
这种定义概率的方式就叫做Gibbs分布。
这里的问题就来了,假设我们现在有10个点,那么Y和X的取值各有2种,那么上述的组合一共就有$4^10$种,这显然是让人无法接受的,所以概率图的问题就是在求解上十分复杂,需要用到变分或者MCMC的思想。
此外,我们再回来看条件分布,能量到底要怎么计算呢?这是CRF模型第二个比较难求解的地方,一般来说,能量被定义为两部分:X对于Y的直接能量和Y之间的能量。对于第一部分描绘的是在当前X下得到当前Y的能量值,而对于第二部分,则描绘了Y之间的联系,我们往往希望同时为1的Y之间的联系更大,而总是为不同值的Y之间没有联系,甚至需要让他们是负联系。
而这里其实有几个问题可以解答:
1.有没有更优于全连接CRF的结构,也就是我们是否可以预先限定Y之间的关系,然后进一步描绘他们的关系?
2.对于每一张图,我们其实都有一组独特的X,Y,如果我们可以定义一种能量函数和X有关,是不是就可以针对不同样本实现不同的关系图?
2021年11月24日
scGCN is a graph convolutional networks algorithm for knowledge transfer in single cell omics
NC 2021 和之前的文章DSTG: deconvoluting spatial transcriptomics data through graph-based artificial intelligence 是同一个作者,上一篇文章发表到了Briefings in Bioinformatics,这篇发到了NC上。属于一个模板应用到了两个问题上,在DSTG里,作者要预测的是每个spot细胞类型的组成,相当于整个softmax函数都是有用的,而在这篇文章里,作者主需要找出softmax里最大的值,来决定单个细胞的细胞类型。
2021年11月25日
DISCO: a database of Deeply Integrated human Single-Cell Omics data
NAR 2021 一个构建单细胞整合数据库的文章,网址在https://www.immunesinglecell.org/。作者认为现在的细胞图谱(数据库)的问题主要有:1.数据没有进行整合,这包括了在metadata信息上不统一以及在batch效应上没有做去除。2. 细胞类型标注没有进行统一化,3. 在数据的展示和分析上做的不好,比如用户没法用图谱分析自己的数据。其实这三个问题就是他们对应的亮点。
在做的工作上,他们从Fastq文件开始整合单细胞数据,据说收集了1800万个细胞,他们对细胞做了统一的Metadata和Annotation信息。文章的后半部分主推了他们的3个工具: FastIntegration, CELLiD和 CellMapper。这几个顾名思义,是整合,标注,映射工具。这几个工具上他们做了一些很漂亮的优化,提高了运算效率。

2021年11月26日
Lightweight Probabilistic Deep Networks
CVPR 2018 Mark一下这篇文章,没有看完。作者主要提出了一种轻量化的概率化网络输出以及中间神经元变量的框架。作者一开始提出的最简单解决方案就是对输出后的每一个神经元都加入一个方差参数,并假设他们都服从高斯分布。这样模型的输出不仅有分类或者预测的结果,同时还会输出不确定性。这里作者给出了例子:

接下来文章里作者认为如果要把网络中间的参数概率化,需要用到 assumed density filtering (ADF)技术,这是贝叶斯在线学习里一个很经典的方法,ADF是在人工智能、统计、控制论等多个领域里,先后被独立提出发表的。具体的解释可以参考知乎经典模型1. ADF: 增量贝叶斯与在线学习(Online Bayesian Learning) - 知乎 (zhihu.com)的讲解,说的非常清楚,并且其中最有意思的应该是这个一阶矩和二阶矩相等,就是变分的最优解这个结论了。

文章评论